Traitement de la parole (parlée); Analyse et synthèse sonores
On (les humains) parlait avant d'écrire, ce sujet EST important. Nos contacts avec le son sont beaucoup plus important qu'avec l'écriture.
On voit des serveurs vocaux, capables de piloter la conversation d'un organisme commercial et un client mécontent : "Si vous voulez égorger notre directeur, dites : égorger", etc. On a besoin de conversions parole ↔ texte, l'indexation des textes (dans le cadre scientifique ou artistique, mais aussi autre, par ex. par la police [échantillons de voix ; phrases dangereuses...), ou simplement les livres sonores pour les déficients visuels. (Ici la qualité est importante).
Donc, analyse ET synthèse sont nécessaires... Les livres audio modernes, pré-registrés, sont parfois équipés avec un système de pilotage par des commandes vocales.
Il y a des similitudes entre les documents écrits et sonores (par ex., la possibilité de conversion signifie qu'il y a une affinité entre les deux, la relation entre les phonèmes et les lettres est profonde. Les documents sont typiquement dans UNE langue nationale, si on ne la connaît pas - pas de compréhension. Cependant les techniques d'analyse et de synthèse dans le cas du son impliquent la physique de signaux, la connaissance de la physiologie des cordes vocales, etc., et ceci peut être le sujet d'un cours semestriel complet.
Normalement on ne s'occupe pas trop des questions syntaxiques à ce niveau-là (éventuellement, après la reconnaissance des mots, et la conversion en texte). Par contre, tout le domaine de prosodie, l'inflexion de la voix, l'intonation, la mélodie... – tout ceci est absent dans le texte écrit.
Un peu d'histoire...
La bande passante normalisée pour la voix est entre 300 et 3400 Hz, 3 octaves et demi, beacoup moins que pour la musique ; on n'a pas besoin d'un équipement acoustique sophistiqué pour rendre la voix, ou un signal acoustique de synthèse qui ressemble à une voix réelle.
L'analyse du son demande l'exécution de la transformée de Fourier du signal, c'est un domaine récent, mais la synthèse, l'émulation sérieuse est assez ancienne, date du XVIII siècle, si on oublie les sources médievales, peu fiables, qui tracent le domaine jusqu'aux XI – XIII siècles, avec Albertus Magnus et Roger Bacon. En 1769 un inventeur allemand/danois, travaillant en Russie, Christian Gottlieb Kratzenstein a construit un mécanisme vibratoire avec des tuyaux et cavités résonantes, capables d'émuler les voyelles a-e-i-o-u.
À la même époque le célèbre inventeur et tricheur, Johann Wolfgang von Kempelen (le créateur du Turc Mécanique, qui "jouait aux échecs" grâce à un humain caché) a créé aussi une machine capable d'engendrer des mots intelligibles. Elle était très compliquée, et il fallait un opérateur humain pour opérer ses registres. C'est une pièce de musée (Munich) et fonctionne encore !
Deux cents ans après ('197X), j'ai eu l'occasion d'entendre la synthèse de la voix sur les ordinateurs, un "grand" (ICL 1900), et un micro (Sinclair Spectrum, 48K de mémoire, qui jouait aux échecs, et disait : "bien bien, il faut que je réfléchisse..."). Ils n'avaient aucune carte sonore, aucun générateur d'onde, seulement un primitif haut-parleur branché à une sortie digitale 0-1, sans modulation d'amplitude. Comment était-ce possible?
Jouer de la "musique" avec n'importe quoi est connu depuis des millénaires...
Voici comment transformer des choses quelconques en "instruments musicaux". Le but de cet exercice est seulement de montrer que notre appareil auditif est assez tolérant concernant les détails du son, et avec un peu de filtrage par notre physiologie et notre cerveau, la reconnaissance peut être étonnement efficace.
Ces échantillons ont été importés de l'Internet (une centaine de sources, j'ignore l'auteur...), mais on peut faire des choses similaires chez nous, en software. [test vibwave.py]
Le son dans sa repr. typique est une séquence de nombres représentant l'amplitude échantillonnée.
La discrétisation est double : le temps et les valeurs sont discrets. Pour une bonne qualité du son, le taux d'échantillonnage typique/minimal est : 44100 Hz. Selon la loi de Nyquist, ceci doit être au moins le double de la fréquence la plus haute, si on ne veut pas des fréquences fausses (aliasing). Nos limites physiologiques sont entre 20 et 20000 Hz. Le codage raisonnable des valeurs est en 16 bits. Ceci dit, en 8 kHz et 8 bits de discrétisation (qualité "téléphone") la voix est compréhensible. ; Le rapport de tailles des fichiers .wav est 10/1.
Peut-on aller jusqu'à la quantisation en 1 bit, et faire parler (ou jouer Brahms) un marteau-piqueur? La réponse est donnée par le codage PDM (pulse density modulation). Voici l'algorithme qui remplace une valeur haute (>0 initialement) par 1, et basse par -1. Puisque ainsi les erreurs de quantisation s'accumulent, on fait la correction similaire à "dithering" de Floyd-Steinberg en Imagerie.
def pdm(y): # Input.
nn=len(y)
y=y.astype('float')
y=y/max(max(y),abs(min(y)))
q=zeros(nn); err=0
for i in range(nn):
v=y[i]; q[i]=2*(v>err) - 1; err+=q[i]-v
return q
Voici le résultat d'un simple test visuel :
... et de notre chanson - test : . Ceci est très bruité, mais presque acceptable si besoin. De plus, on peut améliorer la qualité du son par le filtrage passe-bas qui élimine hautes fréquences (le sifflement). [Tester rwave.py; Wavosaur]
On observe que la présence de quelques fréquences caractéristiques est essentielle pour la reconnaissance du caractère des voyelles ; le rapport des amplitudes peut varier, notre système auditif est "tolérant".
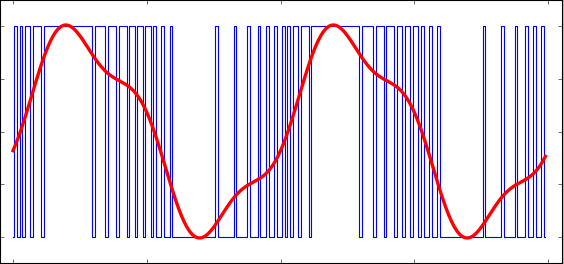
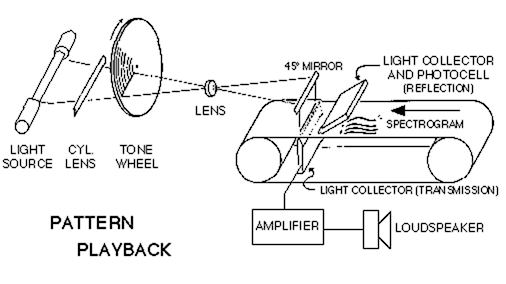
Ceci a encouragé Franklin Cooper qui a construit déjà en fin des années '1940 (Haskins Labs.) un appareil capable de lire optiquement le spectrogramme d'une séquence sonore (la distribution des fréquences dans le temps, faite à l'aide de la transformée de Fourier fenêtrée), et ensuite de piloter un dispositif mécanico-optique, qui engendrait ces fréquences.
Les résultats étaient suffisamment impressionnants, pour encourager la recherche dans ce domaine.
est monotone, pas de prosodie, mais, justement, a contribué aux travaux sur la relation entre l'intonation, essentielle pour communication et assez intuitive, et les propriétés physiques du son.
Il faut parler de spectrogrammes, ou de sonogrammes. Tout est basé sur l'idée de la transformée de Fourier, qui (selon vous) vous n'est pas connue. Pour une fonction du temps \(f(t)\), qui représente une amplitude, sonore ou autre, sa transformée est définie par \(g(s) = \int_{-\infty}^\infty{f(t) e^{ist}dt}\). Plusieurs variantes existent, avec plusieurs coefficients ici et là, et la variante "informatique" est basée sur la transformation des séquences discrètes, tableaux [0 : N-1]. \(f_n\) est une fonction échantillonnée, et sa transformée est un autre tableau,
$$
g_k = \sum_{m=0}^{N-1} f_m \exp(\frac{2\pi i k\cdot m}{N})\,.
$$
Les valeurs de \(f\) sont des poids de composantes harmoniques, oscillantes (sin et cos, ensemble dans l'exponentielle complexe). Si une seule fréquence est présente, le \(f\) est une sinusoïde, le résultat est presque partout vide, sauf un élément. Si la fonction est un bruit aléatoire, sa transformée contiendra beaucoup de fréquences hautes. [test fourier0.py]
Il est évident que la transformée d'une longue séquence sonore, d'un morceau de musique, un discours politique, etc., n'est pas pertinente à quoi que ce soit, car la distribution des fréquences change avec le temps. Mais si le son est découpé en tranches de petite longueur, disons de 2048 éléments, ce qui avec le taux d'échantillonnage égal à 44100 Hz, correspond à 0.046 secondes, on aura une information spectrale locale. La valeur absolu de la FT est tracée verticalement, comme une intensité de couleur, et la fenêtre temporelle "glisse" horizontalement, ce qui donne le sonogramme montré ci-dessus.
La présence de lignes presque horizontales, assez fortes et persistantes, signifie qu'une ou quelques fréquences dominent pendant un certain temps. On les appelle formants, et ils caractérisent les voyelles.
La structure détaillée du sonogramme dépend de la largeur de la fenêtre, de la présence du bruit ambiant, etc., mais on voit clairement qu'une reconnaissance approximative automatisée n'est aucune magie noire. Les formants aident à construire les patterns de reconnaissance des mots.
Text-to-Speech : où est-on?
Les formants et les résonances plus fins (il ne faut pas les confondre) se forment dans les cavités de notre trait vocal, la bouch, le nez, etc. et ceci soupçonnait déjà von Kempelen, à l'époque quand on pensait que la voix est formée principalement par le larynx (et on ne l'écoutait pas à cause de son "Turc")... Les formants permettent de créer des combinaisons de voyelles qui n'existent pas, inventer des nouveaux phonèmes, et le progrès dans ce domaine continue. Cependant, pour des systèmes de "production", la solution qui donne des sons plus naturels, est basée sur les phonèmes pré-registrés à partir d'échantillons réels. Ce ne sont pas seulement les "phones", par ex. "a" tout court, mais également diphones, qui représentent le passage entre un phonème et un autre : "au", "oss", etc.
Bien sûr, ceci sert uniquement à la synthèse, on ne peut utiliser les agglutinations comme ça pour la reconnaissance de la parole.
Le projet qui mérite votre attention, et qui exploite les diphones et les techniques de concaténation, est MBROLA, Laboratoire TCTS de la Faculté Polytechnique de Mons (Belgique). [C'est d'eux que j'ai pris la chanson de Noël, et la "Claire Fontaine"]. Ils veulent constituer une large base de fragments dans plusieurs langues, et les rendre accessibles librement à des buts non-commerciaux [et non-militaires].
Un paquetage Matlab TSTBox, utilisé dans l'enseignement, TTS de Thierry Dutoit, est disponible en téléchargement, et accompagné d'une raisonnable documentation (voir aussi le livre de son auteur, mais il n'est pas gratuit ; c'est un imposant ouvrage).
Afin de pouvoir travailler dans le domaine de synthèse sonore des textes, il faut connaître bien l'analyse des textes ! Avant d'accéder aux phonèmes, il faut identifier la structure morphologique des mots, et ceci dépend énormément de la langue en question. L'identification des diphones éligibles demande la connaissance des abréviations sonores des morphèmes écrits (un diphone est loin de : "deux lettres voisines").
En français il y a la liaison, l'élision des consonnes, etc. Ailleurs, la prononciation dépend du contexte de manière imprévue, comparez en anglais : "bought", cough", "dinghy", "through"... Il faut constituer un bon dictionnaire d'exceptions.
Finalement, sur le plan global, la prosodie : la modulation, l'inflexion de la voix, est un sujet très riche. Un signe de ponctuation peut changer la prononciation de la moitié de la phrase, il faut programmer la voix descendante, ou montante (interrogation), ou les points de suspension... Les travaux dans ce domaine continuent sans arrêt. Et si on veut à ce votre programme chante, donc qu'il adapte les fréquences de base à une ligne mélodique, il faut également connaître un peu de solfège...
Le paquetage MBROLA est disponible dans plusieurs versions et variantes, avec exemples.
Solutions Web, utilisables par tous.
La compagnie Google s'intéresse par le traitement de la parole depuis longtemps. Google Text-to-Speech pour Android permet d'engendrer les flots vocaux depuis votre mail. Pour votre ordinateur régulier il y a des interfaces navigateur, mais pour nous un certain intérêt représente le paquetage gTTS, utilisable depuis Python, permettant de créer et sauvegarder un fichier .MP3 depuis un texte. Vous pouvez exécuter le programme
from gtts import gTTS
txt1 = """This brief comment by Verne during the final decade
of his life says volumes about the overall quality of his
translations. Scholars now unanimously agree that the early
English translations of Verne’s Voyages Extraordinaires were
extremely shoddy and often bear little resemblance to their
original French counterparts."""
tts=gTTS(text=txt1,lang='en')
tts.save('fverne.mp3')
et obtenir un flot sonore équivalent.
De toute façon, les deux méthodes mentionnées : la concaténation et la synthèse des formants, dominent dans la synthède de la voix. La qualité des résultats a leur importance commerciale, mais parfois nous aide à comprendre ce mystérieux mécanisme qui est la compréhension de la parole. Le paramétrage des logiciels de synthèse ensuite guide ceux qui travaillent sur la reconnaissance.
La concaténation (diphones etc.) est relativement simple, et même pour les téléphones sous Android on truve une trentaine d'applications pratiquement utilisables. L'essentiel se réduit à des simples étapes : la séparation des mots en patterns plus petits (souvent ceci est tabularisé, placé dans des bases de données préconfigurées) ; et ensuite le choix des diphones correspndant aux patterns. Vous seriez capables de le faire, et les bases MBROLA sont utilisés dans l'enseignements : des étudiants de votre âge font des logiciels de synthèse sonore.
L'usage des diphones élimine les transitions entre les atomes sonores, mais pas complètement. Une bonne liaison entre les phones est essentielle, on ne doit entendre aucun "clic", ni autre chose anormale entre les fragments. Ceci demande l'implémentation du morphing sonore, qui est différent de la transition "cross-fading", l'atténuation du premier son, et l'amplification du second. Une réalisation très superficielle du morphing est faisable pour les sons purs, si on a deux sinusoïdes, on construit l'interpolateur sous forme d'une troisième, qui change la fréquence et l'amplitude, entre les deux.
Pour les sons plus compliqués, on fait l'analyse spectrale, et on essaie de mettre en correspondance les fréquences dominantes, et ensuite on fait comme expliqué. Avec diphones la fin du premier et le début du second doivent être presque identiques.
Pour la science de la voix, les techniques basées sur les formants sont plus intéressantes. Répétons, que quelle que soit la hauteur de la voix (la fréquence principale), les résonances de notre trait vocal favorisent l'apparition de quelques fréquences dominantes dans des endroits précis, et ces pics (d'habitude assez larges) sont stables, et déterminent notre reconnaissance des voyelles [test : formant.exe; SpecAn]
Le dispositif optique de Cooper de l'année 1950 montrant que les patterns spectraux permettant d'identifier la parole ne sont pas très compliqués, a contribué à développer quelques directions de recherche, dont la signification n'est toujours pas évidente.
En particulier, le groupe –, aussi à Haskins Lab. – de Robert Remez, un neuro-psychologue connu, a montré que la compréhension (même approximative) des phrases, est très loin des propriétés physiques du son, qui étaient considérées comme presque évidentes.
En deux mots et un grand clin d'oeil ...: comment établir une conversation avec des extra-teerrestres (Remezians), qui n'ont pas de cordes vocales, ni aucun autre disposif vibratoire compatible avec un générateur des fréquences acoustiques comme nous les connaissons, mais qui savent bien siffler, et même siffler en polyphonie (trois sifflets simultanément)?
Ceci paraît un peu ridicule, mais Remez a remplacé la structure de l'onde sonore riche en harmoniques et bruit de basse fréquence comme chez nous, par quelques : 3 - 4 sons purs, des sinusoïdes un peu modulées.
Il est impossible de localiser les voyelles, consonnes ; il n'y a pas de fricatifs ("s", "f" ...) mais la phrase est reconnaissable ... En voici une autre
La construction de ces 3 ou 4 composantes, avec la variation des amplitudes et de fréquences de chacune, est un cas typique du morphing sonore primitif, réalisable en Python assez facilement.
Cette expérience prouve que la reconstruction du sens des mots est assez indépendante des propriétés physiques du son telles que la distrbution détaillée de fréquences, structure harmonique, etc., que beaucoup de choses se passent dans le cerveau. On constate facilement que la compréhension des phrases des Remezians est considérablement plus facile quand on a entendu d'abord la prononciation humaine.
C'est une constatation importante. On comprend un mot ou une phrase, quand elle est compatible avec nos patterns cérébraux, quand on reçoit ce que l'on attendait, exactement comme avec la lecture (Rappelez-vous de la synthèse des N-grames...). Comme une séquence (locale) de lettres est naturelle ou non, la séquence des phonèmes également ; en fait ceci est contribue à la définition des phonèmes, à la construction des diphones, etc. Dans le domaine symbolique ceci est difficile, mais dans le numérique, c'est un procédé standard.
Linear Predictive Coding
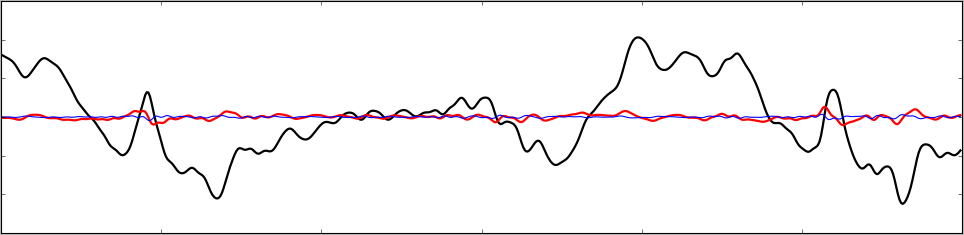
Ceci est la base conceptuelle des techniques de compression du son et des images (déjà brièvement mentionnées) : si le signal est une fonction pas trop chaotique (pas de très hautes fréquences), avec un peu de régularité, au lieu de coder l'amplitude, on peut coder les différences entre les valeurs voisines ; ceci est le codage différentiel (rouge).
On peut faire beaucoup mieux (bleu). Si dans un segment la courbe est presque linéaire, au lieu de coder \(y_i\), on code \(y_i + y_{i-2} - 2 y_{i-1}\), on obtient l'erreur d'approximation linéaire, qui peut facilement réduire la fonction par plusieurs dizaines. Avec non pas deux, mais trois dernières valeurs, et l'approximation parabolique, encore mieux. Il est facile de construire un polynôme d'ordre quelconque (dizaines de coefficients). L'approximation s'appelle toujours "codage linéaire", car on approche la vrai valeur par une combinaison linéaire des valeurs précédentes.
Ceci est l'introduction à l'introduction. L'application réelle du LPC dans le domaine du traitement de la langue est plus compliquée ; on s'intéresse toujours à l'analyse / compression / re-synthèse. On essaie de construire les coefficients de l'approximation pour des tranches temporelles assez longues, non pas ponctuelles, et on cherche la "meilleure approximation". Ceci sert ensuite a séparer les résonances / formants du "résidu", ce qui permet la reconstruction des voyelles, etc. Pour discuter ceci il faut connaître la théorie de filtres numériques, le sens des pôles des filtres, etc. Il faut aussi opérer avec un modèle de génération du son par les humains : la glotte et les cordes vocales qui produisent un
"buzz", et le filtre produisant des résonances, construit par l'LPC.
De telles manipulations datent des années '1930, avec l'équipement électronique analogique (par ex. le Vocoder).
 On (les humains) parlait avant d'écrire, ce sujet EST important. Nos contacts avec le son sont beaucoup plus important qu'avec l'écriture.
On (les humains) parlait avant d'écrire, ce sujet EST important. Nos contacts avec le son sont beaucoup plus important qu'avec l'écriture.
 Le son dans sa repr. typique est une séquence de nombres représentant l'amplitude échantillonnée.
Le son dans sa repr. typique est une séquence de nombres représentant l'amplitude échantillonnée.
 Les résultats étaient suffisamment impressionnants, pour encourager la recherche dans ce domaine.
Les résultats étaient suffisamment impressionnants, pour encourager la recherche dans ce domaine.
){kind=link}
){kind=link}
){kind=link}
){kind=link}