 Ce grand domaine qui est l'ingénierie linguistique a deux "parents" (et un nombre conséquent de "parrains").
Ce grand domaine qui est l'ingénierie linguistique a deux "parents" (et un nombre conséquent de "parrains").
D'un côté, depuis des siècles on essaie de comprendre l'essence de la communication langagière entre les humains : pourquoi cela marche? Quel est le rapport entre les connaissances / l'intelligence / la vision du monde (la cognition) – et le langage? Pourquoi la traduction est possible, et pourquoi elle n'est jamais parfaite?
On essaie donc de modéliser les phénomènes langagiers, les structures de communication et d'apprentissage. On insiste sur le fait que les énoncés linguistiques sont des expressions par excellence humaine, et ceci n'a rien à voir averc les langages formels, artificiels. Les ordinateurs servent ici surtout comme des outils de simulation, et comme des bases de données, avec des dispositifs de recherche et d'analyse statistique.
D'autre part on a besoin d'outils pratiques, de traduction, de la recherche des concordances (par ex. la vérification si X était ou non l'auteur d'un texte vieux de plusieurs siècles...), etc. On a besoin des correcteurs d'orthographe, et des répondeurs automatiques "intelligents". On doit modéliser les langues à l'aide des outils formels, et ici la césure entre les langues naturelles, et les langages formels, devient floue !
On définit des structures lexicales et syntaxiques de manière la plus rigide, et mathématiquement disciplinée possible, afin de pouvoir implémenter des automates de reconnaissance / synthèse adéquats et efficaces.
Le conflit entre ces deux visions est normal. Les expressions linguistiques humaines sont ambiguës. L'ambiguïté, c'est une difficulté majeure pour les implémentations, on doit limiter le non-déterminisme à un strict minimum. De plus, la psychologie des chercheurs en sciences humaines, philosophie, psychologie, etc. est très différente de celle des "matheux", et ceci mène à des malentendus persistants depuis des années...
Pour l'apprentissage initial du TAL dans un contexte informatique, vous devez être formalistes.
Que chaque terme soit bien précis, bien spécifié. Sinon, vous allez confondre des notions de manière exécrable. Voici un exemple (un exercice de l'année dernière. Personne de mon groupe n'a trouvé la solution d'un "dilemme" qui n'est pas un).
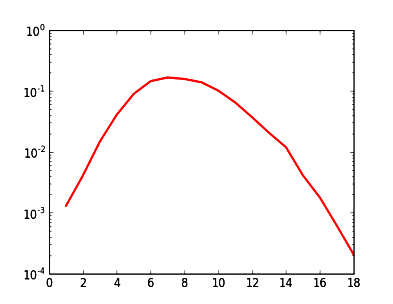 Cherchons dans la littérature, et trouvons la thèse que la répartition des fréquences des mots en français selon leur longueur suit une loi proche de Poisson (ou Gaussienne, \(\exp(-a\cdot x^2)\)) : courbe en forme de cloche, ce qui en échelle logarithmique ressemble à une parabole, présentée sur le graphique à droite.
Ensuite, prenons un texte assez long, par ex. "20000 Lieues sous les mers" de Verne, 150 000 mots. Ceci doit correspondre de manière raisonnable à un texte "typique" en français.
Cherchons dans la littérature, et trouvons la thèse que la répartition des fréquences des mots en français selon leur longueur suit une loi proche de Poisson (ou Gaussienne, \(\exp(-a\cdot x^2)\)) : courbe en forme de cloche, ce qui en échelle logarithmique ressemble à une parabole, présentée sur le graphique à droite.
Ensuite, prenons un texte assez long, par ex. "20000 Lieues sous les mers" de Verne, 150 000 mots. Ceci doit correspondre de manière raisonnable à un texte "typique" en français.
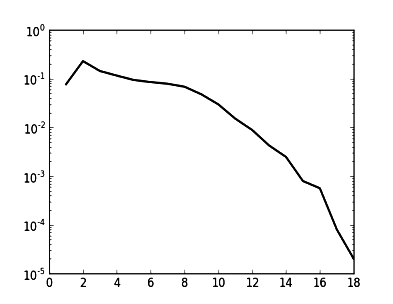 Tokenisons-le (éliminons la ponctuation, les majuscules, etc.), et calculons la distribution des fréquences des mots en fonction de leur longueur.
Le résultat est présenté sur le graphique à gauche [échelle verticale : logarithmique, comme auparavant].
Pourquoi cette pseudo-"contradiction" ? Expliquer, et écrire des programmes qui engendrent ces courbes, à partir d'un texte modèle.
Nous allons travailler dessus. Réfléchissez sur la différence entre les concepts : "fréquence dans un texte", et "fréquence dans une langue".
Voici le début de notre programme (sans garantie...)
Tokenisons-le (éliminons la ponctuation, les majuscules, etc.), et calculons la distribution des fréquences des mots en fonction de leur longueur.
Le résultat est présenté sur le graphique à gauche [échelle verticale : logarithmique, comme auparavant].
Pourquoi cette pseudo-"contradiction" ? Expliquer, et écrire des programmes qui engendrent ces courbes, à partir d'un texte modèle.
Nous allons travailler dessus. Réfléchissez sur la différence entre les concepts : "fréquence dans un texte", et "fréquence dans une langue".
Voici le début de notre programme (sans garantie...)
-
Un peu sur la surface des textes (quand même...): le codage des caractères, et l'Unicode en particulier. Si on se coince ici, le travail devient très pénible.
-
Analyse statistique des textes : répartition des fréquences des lettres, modélisation statistique dans plusieurs langues. Les programmes auront besoin des dictionnaires, et aussi des générateurs de nombres aléatoires, et des outils de visualisation.
On parlera de quelques lois phénoménologiques, comme la loi de Zipf, et comme dans la présentation de ce cours : des textes synthétiques (au début : synthèse purement lexicale, puis : l'usage des mots réels, pour la synthèse d'un discours.)
-
Analyse lexicale structurelle : reconnaissance des mots avec des particularités, par ex. les adresses mail ou les URLs, les nombres réels, etc. Nous allons apprendre à utiliser les expressions régulières, et le module re de Python. Ceci sera très utile pour la tokenisation des textes.
On parlera aussi des automates de reconnaissance. Tout ceci vous sera également utile en L3, en cours de compilation.
-
Analyse des similitudes entre les mots, la distance de Damerau-Levenshtein, et son utilité pour les correcteurs d'orthographe. Son implémentation récursive est très compacte, mais pas si facile à comprendre... (Itérative "standard" est pire !))
Représentation structurelle "connectée" des mots ; dictionnairs de recherche basés sur les tries : des structures hiérarchiques, arborescentes, qui gardent ensemble les mots qui partagent le même préfixe. (Utile pour le stockage de plusieurs formes grammaticales).
-
Grammaires et analyse syntaxique, structuration des phrases. Nous commencons par les grammaires non-contextuelles, typiques pour les langages formels, pour l'analyse syntaxique des programmes en compilation ; ensuite nous essaierons de généraliser ces grammaires. L'approche "structurelle" complémente les outils statistiques.
L'année dernière (2014-2015) nous avons travaillé sur plusieurs exercices (rarement complétés...)
-
L'usage du paquetage NLTK pour la recherche des synonymes, et autre classification hiérarchique des mots.
-
Construction des automates pour la coupure automatique des mots, à l'aide de patterns utilisé par le système TeX.
-
Visualisation des structures hiérarchiques dans l'espace hyperbolique à l'aide d'un joli applet : Treebolic.
-
Construction d'un petit moteur de recherche, basé sur les paquetages disponibles sur le Web pour effectuer le "crawling" des pages liées, et pour leur indexation.
-
Cette année, peut-être, nous arriverons à travailler sur l'implémentation des Tag Clouds (exemple sur la première page de ces notes), ou autres techniques de mise en relief des fragments importants des textes.
- Aussi, peut-être, nous aborderons un peu de traduction automatisée...
La vitesse de notre travail dépend de vous. Comme je l'ai déjà dit, cette option est pour les étudiants ambitieux, avec imagination, qui aiment la littérature (et la culture en général), et qui n'ont pas peur d'outils mathématiques non plus.
(Et qui ne craignent pas les langues étrangères. Je suis très sérieux.)
Quelques mots sur la recherche dans ce domaine
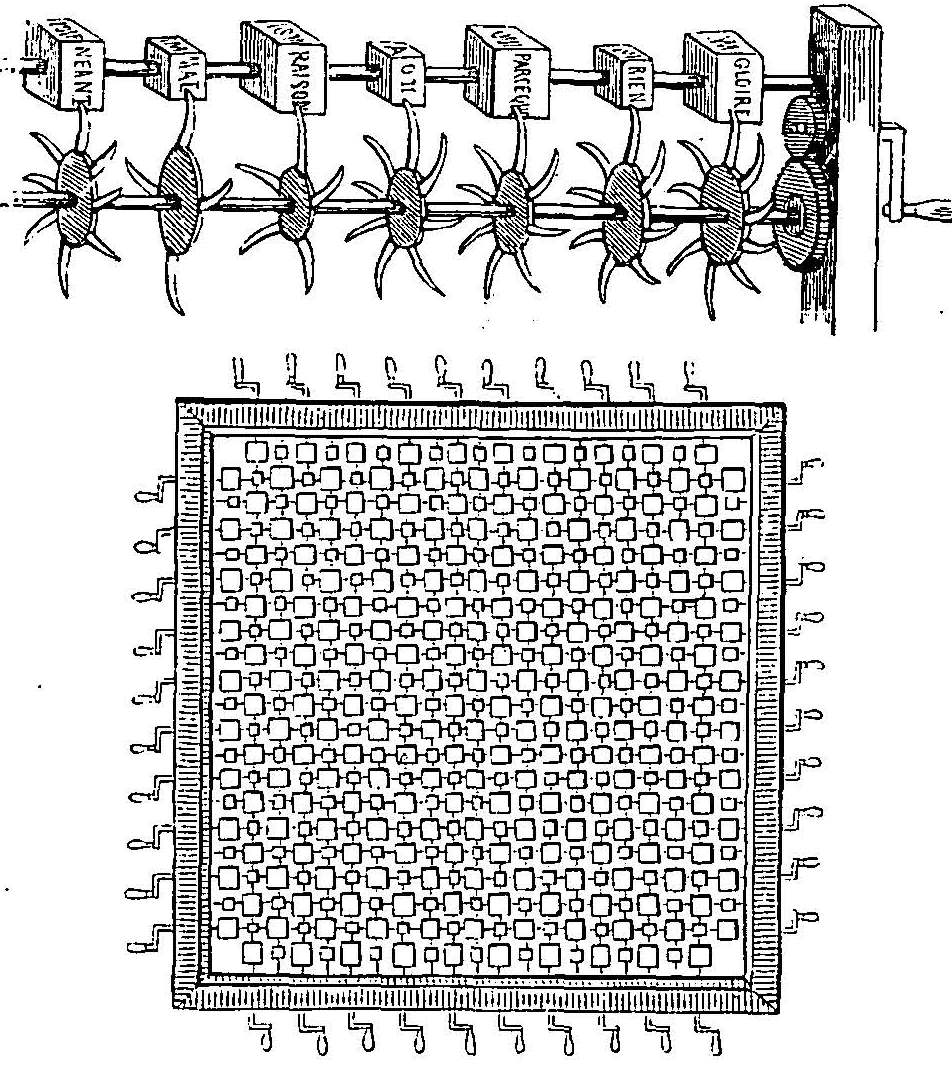 L'automatisation du traitement, de la compréhension et de la génération des énoncés langagiers, est un mythe vieux de plusieurs siècles. Dans "Les Voyages de Gulliver" (1721) on trouve dans l'Académie de Laputa, une machine capable de produire des discours par l'arrangement aléatoire des mots, suivi d'un filtrage préservant une certaine cohérence. Swift ne se rendait pas compte que ce jeu littéraire, cynique et méchant vis-à-vis les "savants", deviendra un jour un vrai outil ! Et on dit que cette problématique est née avec les travaux de Shannon (1948) et Turing (1950)?...
Ce dernier, avec son célèbre "test de Turing" a lancé la thèse que la faculté de maintenir une conversation, donc de comprendre et d'engendrer des textes dans une langue naturelle, est l'essence même de l'intelligence humaine, et permet de distinguer une machine d'une entité pensante.
Ceci n'est pas considéré comme une vérité philosophique, mais a ouvert un grand domaine de recherche.
Comment pouvons nous apprendre à nous exprimer, et à comprendre les autres [une autre question : pourquoi nos politiciens s'expriment de manière merveilleuse, mais ne pigent strictement rien de ce que l'on leur dit, est un problème scientifique d'envergure, qui donnera sûrement le prix Nobel à quelqu'un. Est-ce que l'un de vous veut travailler dessus?...]
Il faut concevoir un modèle de la langue, et aussi formaliser ce modèle, de manière à pouvoir implémenter ses réalisations concrètes. On a travaillé dans plusieurs directions, afin de pouvoir faire des "robots" comme Eliza de Weizenbaum (1966), qui construisait des phrases à partir des fragments des énoncés de l'interlocuteur (et simulait un psychothérapeute). Il fallait savoir faire des structures correctes sur le plan syntaxique, donc on a profité aussi de la formalisation des grammaires, même si l'influence des travaux de Chomsky (années '50 – '90), absolument essentiels pour les langages formels (et important dans les sciences cognitives en général), s'est avérée plutôt limitée dans la modélisation du domaine de langues naturelles.
D'ailleurs, on ne sait toujours pas si l'évolution a intégré dans nos cerveaux des "modules grammaticaux", des tissus / structures neuronales spécialisées, ou si c'est un épi-phénomène...
L'automatisation du traitement, de la compréhension et de la génération des énoncés langagiers, est un mythe vieux de plusieurs siècles. Dans "Les Voyages de Gulliver" (1721) on trouve dans l'Académie de Laputa, une machine capable de produire des discours par l'arrangement aléatoire des mots, suivi d'un filtrage préservant une certaine cohérence. Swift ne se rendait pas compte que ce jeu littéraire, cynique et méchant vis-à-vis les "savants", deviendra un jour un vrai outil ! Et on dit que cette problématique est née avec les travaux de Shannon (1948) et Turing (1950)?...
Ce dernier, avec son célèbre "test de Turing" a lancé la thèse que la faculté de maintenir une conversation, donc de comprendre et d'engendrer des textes dans une langue naturelle, est l'essence même de l'intelligence humaine, et permet de distinguer une machine d'une entité pensante.
Ceci n'est pas considéré comme une vérité philosophique, mais a ouvert un grand domaine de recherche.
Comment pouvons nous apprendre à nous exprimer, et à comprendre les autres [une autre question : pourquoi nos politiciens s'expriment de manière merveilleuse, mais ne pigent strictement rien de ce que l'on leur dit, est un problème scientifique d'envergure, qui donnera sûrement le prix Nobel à quelqu'un. Est-ce que l'un de vous veut travailler dessus?...]
Il faut concevoir un modèle de la langue, et aussi formaliser ce modèle, de manière à pouvoir implémenter ses réalisations concrètes. On a travaillé dans plusieurs directions, afin de pouvoir faire des "robots" comme Eliza de Weizenbaum (1966), qui construisait des phrases à partir des fragments des énoncés de l'interlocuteur (et simulait un psychothérapeute). Il fallait savoir faire des structures correctes sur le plan syntaxique, donc on a profité aussi de la formalisation des grammaires, même si l'influence des travaux de Chomsky (années '50 – '90), absolument essentiels pour les langages formels (et important dans les sciences cognitives en général), s'est avérée plutôt limitée dans la modélisation du domaine de langues naturelles.
D'ailleurs, on ne sait toujours pas si l'évolution a intégré dans nos cerveaux des "modules grammaticaux", des tissus / structures neuronales spécialisées, ou si c'est un épi-phénomène...
Les modèles statistiques exploitaient les probabilités des phonèmes, mots, fragments de phrases dans une langue. Ces probabilités sont très déséquilibrées, les corrélations entre une entité et ses voisins sont énormes.
Ma page de présentation montre que les combinaisons de 3 lettres ou de 3 mots produisent des textes "lisibles" ! Ceci a commencé en 1948 avec Shannon, mais dans les années '90 cette approche a subi une forte évolution, elle s'est avérée précieuse pour la recherche et la structuration des informations "en vrac" (la fouille des données, ou data mining).
[Je suis convaincu que ce texte fera partie d'une belle collection de la CIA, car il contient des termes pas si courants, et dont l'importance est augmentée par leur fréquence. Je suis en train de faire une bombe atomique, oui, une bombe atomique a de buts terroristes, car je l'aime bien, les bombes atomiques, et j'attaquerai mes ennemis religieux avec cette bombe atomique, dès que l'occasion se présente.].
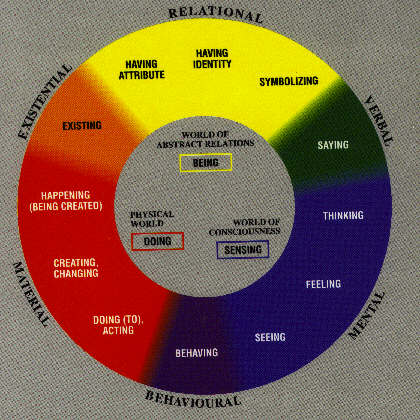 Une autre tendance : connexionniste a aussi vu le jour, encouragée par les travaux sur les réseaux neuronaux. Ceci sert à modéliser les processus cognitifs comme des amas de "noeuds", qui s'activent en recevant des données, et activent autres unités. Cette approche ne modélise pas la langue, mais ici elle peut être vue comme un "réseau" de relations entre les mots.
Son protagoniste, M. Halliday a d'ailleurs fort critiqué l'approche structurelle, style Chomsky. Ses spéculations sont difficilement formalisables.
Une certaine tendance connexionniste est visible dans des travaux et applications où on cherche les relations : synonymes, hypo- et hypernymes, catégories, instances... entre les mots, comme dans la base lexicale Wordnet.
Cette applet Java, Treebolic de Bernard Bou, est un excellent outil de visualisation des graphes (surtout arborescents) des relations. En principe Treebolic n'a rien à voir avec Wordnet, mais son utilité est évidente. (Un projet optionnel de l'année dernière était basé sur l'usage de Treebolic, et je pense continuer cette idée).
Une autre tendance : connexionniste a aussi vu le jour, encouragée par les travaux sur les réseaux neuronaux. Ceci sert à modéliser les processus cognitifs comme des amas de "noeuds", qui s'activent en recevant des données, et activent autres unités. Cette approche ne modélise pas la langue, mais ici elle peut être vue comme un "réseau" de relations entre les mots.
Son protagoniste, M. Halliday a d'ailleurs fort critiqué l'approche structurelle, style Chomsky. Ses spéculations sont difficilement formalisables.
Une certaine tendance connexionniste est visible dans des travaux et applications où on cherche les relations : synonymes, hypo- et hypernymes, catégories, instances... entre les mots, comme dans la base lexicale Wordnet.
Cette applet Java, Treebolic de Bernard Bou, est un excellent outil de visualisation des graphes (surtout arborescents) des relations. En principe Treebolic n'a rien à voir avec Wordnet, mais son utilité est évidente. (Un projet optionnel de l'année dernière était basé sur l'usage de Treebolic, et je pense continuer cette idée).
Nous ne pourrons aborder qu'un pourcentage infime du sujet, et nous devons abandonner complètement le traitement (reconnaissance et synthèse) des flots vocaux, de la parole, car on aurait besoin d'un semestre du traitement de signaux, sans parler ds cours de phonétique, de la théorie des processus stochastiques, etc. Mais c'est un sujet vraiment fascinant.
Les chapitres suivants, sont :
-
Un peu sur le codage des textes plurilingues. Unicode et UTF-8
-
Traitement statistique des textes. Une introduction aux concepts probabilistes avancées (probabilités conditionnelles, processus de Markov...) est indispensable.
-
Analyse lexicale, et expressions régulières.
-
Grammaires et analyse syntaxique. (Et aussi la synthèse pilotée par la syntaxe).