Solutions
Fréquence des mots dans un texte (Verne)
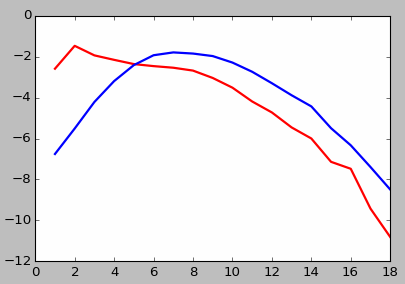 Voici le programme qui calcule les fréquences dans le texte de Verne. On commence par le nettoyage, l'élimination de la ponctuation, et la séparation des mots. En particulier, nous éliminons les noms des chapitres en chiffres romains, à l'aide des expressions régulières. Vous ne les connaissez pas encore, mais on y arrive...
Voici le programme qui calcule les fréquences dans le texte de Verne. On commence par le nettoyage, l'élimination de la ponctuation, et la séparation des mots. En particulier, nous éliminons les noms des chapitres en chiffres romains, à l'aide des expressions régulières. Vous ne les connaissez pas encore, mais on y arrive...
Le résultat est le dictionnaire des mots d avec leurs fréquences.
import re
from pylab import *
sg=sg.replace("\n"," ")
sg=re.sub("[XVI]+\s", '', sg)
# non-lettres
sep=".,'!:;\n0123456789-_()°?«»&|<>"+'"'
rs=sg.lower()
for c in sep: rs=rs.replace(c,' ')
l=rs.split()
d={}
for m in l: d[m]=1+d.get(m,0)
Ensuite, pour dessiner la répartition des fréquences des mots dans le texte, séparons les clés (l'axe horizontal) et les valeurs.
dt={}; sm=0
for m in d:
lm=len(m)
sm+=d[m]
dt[lm]=d[m]+dt.get(lm,0)
for lm in dt: dt[lm]/=sm
Par contre, si nous voulons la répartition des mots dans la langue, chaque mot dans le dictionnaire d compte une seule fois, quel que soit le nombre de ses occurrences dans le livre.
dl={}; sm=0
for m in d:
lm=len(m)
sm+=1
dl[lm]=1+dl.get(lm,0)
for lm in dl: dl[lm]/=sm
Le reste c'est la récupération des valeurs et le dessin.
def dat(dic):
ls=sorted(list(dic.items()))
ks,lg = zip(*ls)
if ks[0]==0: # mots impossibles
ks=ks[1:]; lg=lg[1:]
ks=array(ks)
lg=log(array(lg))
return (ks,lg)
ks,lg = dat(dt)
ks1,lg1 = dat(dl)
plot(ks,lg,'r',ks1,lg1,'b',lw=2)
show()
 Voici la vérification de la dernière distribution à l'aide d'un dictionnaire français (liste de mots)
Voici la vérification de la dernière distribution à l'aide d'un dictionnaire français (liste de mots)
fg = open("../Textes/liste_mots.txt","r",encoding='utf-8')
d={}; sm=0
for m in fg:
t=m.split()[0]
n=len(t)
d[n]=1+d.get(n,0)
sm+=1
for lm in d: d[lm]/=sm
Si on affiche les résultats de Verne et ceux de la liste de mots, on constate une bonne concordance. Seulement le dictionnaire contient quelques mots superexécrabilissimes que l'on ne trouve dans des textes normaux, ainsi que des pseudo-mots très courts de 2 lettres, comme "aa".
La théorie statistique correspond bien à la réalité.
Analyse d'un texte HTML à l'aide de la BeautifulSoup
Ce module ajoute une bonne dose de "sens commun" aux parseurs XML/HTML. Dans l'exemple ci-dessous nous utilisons lxml (chargé automatiquement, à condition d'être présent dans le système).
import bs4
tf=open("../Master.html",'r',encoding="UTF-8")
tx=tf.read()
soup=bs4.BeautifulSoup(tx,'lxml')
links = soup.find_all('a')
for rf in links:
print(rf.get('href'))
La "soupe" est une structure qui représente le document, avec des propriétés hiérarchiques facilement récupérables. Le résultat affiché, avec la version courante de mon Master.html, est :
https://dias.users.greyc.fr/?op=paginas/tal.html
../PyObj/Master.html
https://store.continuum.io/cshop/anaconda/
http://nltk.org/
http://nltk.org/book/
tp0709.html
tp2109.html
tp2809.html
javascript:lgo('Pres15.html','Ltal')
javascript:lgo('Intro0.html','Ltal')
javascript:lgo('Stati.html','Ltal')
javascript:lgo('Nstati.html','Ltal')
javascript:lgo('Analex.html','Ltal')
javascript:lgo('Struct.html','Ltal')
javascript:lgo('Anasyn.html','Ltal')