LTAL, Projet : Wordnet, visualisation arborescente
Idée : Ceci est un projet plus complet, basé sur nos travaux sur Treebolic et le chargement des hiérarchies du Wordnet sous NLTK. On a travaillé un peu avec les hyponymes, mais ici il s'agit uniquement des synsets, des relations sémantiques "parallèles", des concepts liés l'un avec l'autre.
 Vous devez écrire un programme Python, qui engendre un document Treebolic, en format .xml, contenant les mots-clés (lemmatisés, Wordnet s'en occupe...) décrivant un concept répertorié par Wordnet, avec ses relations.
Les noeuds pourront contenir les liens qui mèneront à leurs descriptifs dans Wikipédia, ou à Google, ou à d'autres sources d'information encyclopédique, mais ceci sera laissé pour un autre projet.
(Peut-être un projet individuel en L3?)
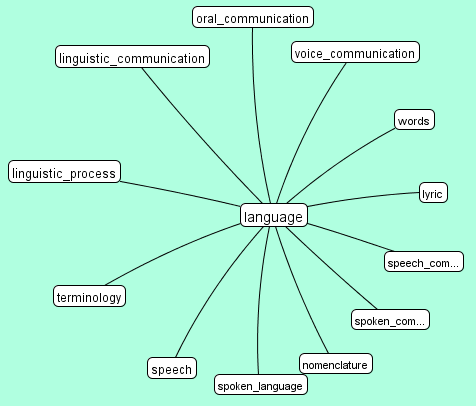
En quelques mots : Vous choisissez un mot, par ex. "language", et le programme accède à wordnet, et trouve la liste de synsets correspondante. On ramasse les noms lemmatisés (lemma_names) de tous les mots "autour", et on les dessine à côté du mot original : la racine du graphe.
Mais l'avantage d'un système comme Treebolic consiste à pouvoir visualiser des hiérarchies plus profondes et volumineuses.
Si pour chaque mot trouvé : "terminology", "speech", "words", etc. on récupere leurs synsets, et on attache au noeud correspondant, on pourra facilement construire un réseau sémantique avec des milliers de composantes. Regardez cette applet, où l'arborescence a la profondeur 4.
Vous devez écrire un programme Python, qui engendre un document Treebolic, en format .xml, contenant les mots-clés (lemmatisés, Wordnet s'en occupe...) décrivant un concept répertorié par Wordnet, avec ses relations.
Les noeuds pourront contenir les liens qui mèneront à leurs descriptifs dans Wikipédia, ou à Google, ou à d'autres sources d'information encyclopédique, mais ceci sera laissé pour un autre projet.
(Peut-être un projet individuel en L3?)
En quelques mots : Vous choisissez un mot, par ex. "language", et le programme accède à wordnet, et trouve la liste de synsets correspondante. On ramasse les noms lemmatisés (lemma_names) de tous les mots "autour", et on les dessine à côté du mot original : la racine du graphe.
Mais l'avantage d'un système comme Treebolic consiste à pouvoir visualiser des hiérarchies plus profondes et volumineuses.
Si pour chaque mot trouvé : "terminology", "speech", "words", etc. on récupere leurs synsets, et on attache au noeud correspondant, on pourra facilement construire un réseau sémantique avec des milliers de composantes. Regardez cette applet, où l'arborescence a la profondeur 4.
Préparatifs
Puisque on attend de vous un sérieux travail off-line (peut-être deux demi-journées, ou un peu plus), installez sur vos ordinateurs le paquetage NLTK (version adaptée à votre version de Python), lancez-le :
import nltk as nl
nl.download()
Le Downloader du NLT peut être textuel ou graphique, selon le système. Il faut charger au moins book (c'est une collection avec plusieurs exemples et utilités) et wordnet. Vérifiez ; après : from nltk.corpus import wordnet as wn, exécutez
>>> wn.synsets('computer')
[Synset('computer.n.01'), Synset('calculator.n.01')]
>>> wn.synset('computer.n.01').definition
'a machine for performing calculations automatically'
>>>
ou autres choses, peut-être trouvées dans le livre de Bird, Klein et Loper sur NLTK : "Natural Language Processing with Python", accessible en ligne. (La version PDF, si besoin, est également disponible).
 Installez Treebolic (Paquets installables se trouvent aussi ici). Sur Windows lancez l'installateur .exe, sous Linux, exécutez
Installez Treebolic (Paquets installables se trouvent aussi ici). Sur Windows lancez l'installateur .exe, sous Linux, exécutez
java -jar treebolic-2.0.6/treebolic-installer-2.0.6-20130131.jar
Testez-le
Lancez le générateur, construisez un graphe minimal, comme à droite, avec un noeud et une arête supplémentaire (et l'effacement d'un noeud prédéfini), et regardez le contenu du fichier .xml qui contient sa définition.
Lisez un peu la documentation afin de savoir quels noeuds avec quels attributs engendre et affiche Treebolic. Observez <nodes> ... </nodes> ; <node ...> ... </node> ; label, edges et edge, couleurs, etc. Le rapport entre le graphe et la hiérarchie des balises est évident. L'utilisateur ne se préoccupe pas de la géométrie du graphe (du positionnement des noeuds) ni de l'interaction.
Introduction
Comme il a été présenté en TP, Treebolic représente l'espace hyperbolique à travers le modèle du disque de Poincaré (voir la documentation). Les distances "égales" (par ex. entre un noeud et son descendant direct) diminuent quand ces noeuds s'éloignent du centre. Quand on les met au centre, la zone subit une amplification locale. Ainsi Treebolic est capable de rendre un graphe avec des milliers de noeuds, permettant à l'utilisateur de se focaliser sur une zone locale.
Ceci sera utile pour la représentation d'un réseau de mots en anglais, un dictionnaire sémantique qui constitue le Wordnet. La version française : Wolf de Benoît Sagot et autres, est utilisable, mais elle n'est pas complète.
Le travail peut être décomposé en deux étapes. La première est la création des classes qui représentent l'arborescence sémantique :
-
L'arbre global, avec des données utiles pour l'administration centrale du processus. L'objet (unique) de cette classe représentera le document .xml, et en sera converti lors de la visualisation.
-
La classe des noeuds, chacun avec son contenu (le texte) et autres paramètres locaux, comme la liste des noeuds-descendants.
L'ensemble n'est pas très long. Mon programme-exemple complet compte un peu plus de 100 lignes de code, et est capable d'engendrer l'arbre de profondeur quelconque. Treebolic permet l'ajout d'arêtes supplémentaires entre les noeuds quelconques, mais vous n'en aurez pas besoin, donc pas de section <edges> ... </edges>.
Classes du système
Classe Treebolic
L'objet de cette classe contient l'entête et la fin du document .xml, et construit le document final en accord avec les exemples que vous pouvez regarder dans la doc, ou préparer vous-mêmes. Ses paramètres principaux sont :
-
La racine de l'arbre, son noeud central. Les autres y seront attachés.
-
Optionnellement : la liste complète de tous les noeuds pour la manipulation globale, non-hiérarchique. Pour vous c'est probablement inutile.
-
La couleur du fond.
-
Peut-être, un court préfixe, par ex. "tr_", qui servira à identifier les "ids" de chaque noeud : "tr_0", "tr_1", "tr_2", ... qui doivent être uniques. Puisque, en général, on peut attacher un arbre à un autre, des préfixes différents sont utiles, mais vous n'en aurez pas besoin.
Les méthodes dans cette classe servent principalement à formater les entités balisées, avec ou sans terminaison : "< ... />"
Classe Node
Ceci correspond à un noeud du graphe : <node pars...> ... contenu </node>, où le contenu peut contenir d'autres noeuds, et contient obligatoirement <label>texte</label>. Dans les paramètres on a id=..., backcolor=..., etc.
Donc, les paramètres principaux, sont :
-
Étiquette (label).
-
ID. Ceci peut être directement un texte, ou un nombre, qui formera le texte lors du formatage.
-
Couleur du fond, coluleur de la police.
-
Liste des descendants
-
Optionnellement : le noeud parent. Aussi : le lien vers le conteneur de la classe Treebolic, pour l'administration.
Deux méthodes dans cette classe sont essentielles : la méthode de formatage, et la méthode add(self,enfant), qui ajoute un noeud-enfant au self. Alternativement, on peut définir une méthode qui attache self au noeud parent. Le choix dépend du style de programmation de chacun.
Construction de l'arbre
Ceci est un peu plus compliqué qu l'on n'y pense, à cause de la cyclicité des affinités sémantiques. Un X dans ses synsets peut avoir un Y, qui mène à X. (Par ex., on trouve "language" à l'intérieur de l'arborescence qui a ce mot pour racine). Théoriquement ceci est correct, mais les doublons doivent être obligatoirement supprimés, sinon il y aura trop de répétitions. Une réalisation améliorée devrait produire un lien vers l'arrière, mais afin ne pas charger trop le diagramme, ne le faites pas.
Une procédure, disons attach(mot, arbre, vus, parent, profond), construit la liste de concepts : sns=synsets(mot). La variable vus est un ensemble (set) Python, une collection, qui préserve automatiquement l'unicité de chaque composante. La méthhode add y ajoute un objet seulement s'il n'était pas présent.
Le programme construit une liste de chaînes, en ramassant un set contenant tous les lemma_names de tous les éléments de synsets. Cependent, ensuite on élimine de cet ensemble tout ce qui se trouve dans vus, et immédiatemment après, vus est mis à jour avec cette nouvelle liste.
Pour chaque mot dans la liste on construit un Node p, et on l'attache au parent.
Si le paramètre profond est supérieur à zéro, pour chaque noeud créé, on relance récursivement attach, avec ce noeud comme parent, et profond diminuée de 1. L'argument arbre sert principalement à l'administration globale, la gestion des préfixes, etc.
Soulignons que notre programme affiche les affinités sémantiques, non pas la relation hyponimique suggérée en TP. Ceci serait un autre projet, similaire.
Retour à l'index